不用逃避未来,了解新技术,拥抱变化,找到第二曲线
从产品的角度学习chatgpt,不要太陷入技术层面。
chatGPT发展历程
GPT->GPT2->GPT3趋势:得益于Transformer的设置,GPT模型的层数堆叠更多,参数更大,训练数据更多,得到的效果更好,GPT2和GPT3甚至不用微调,直接测试下游任务,效果也很好。
GPT-1
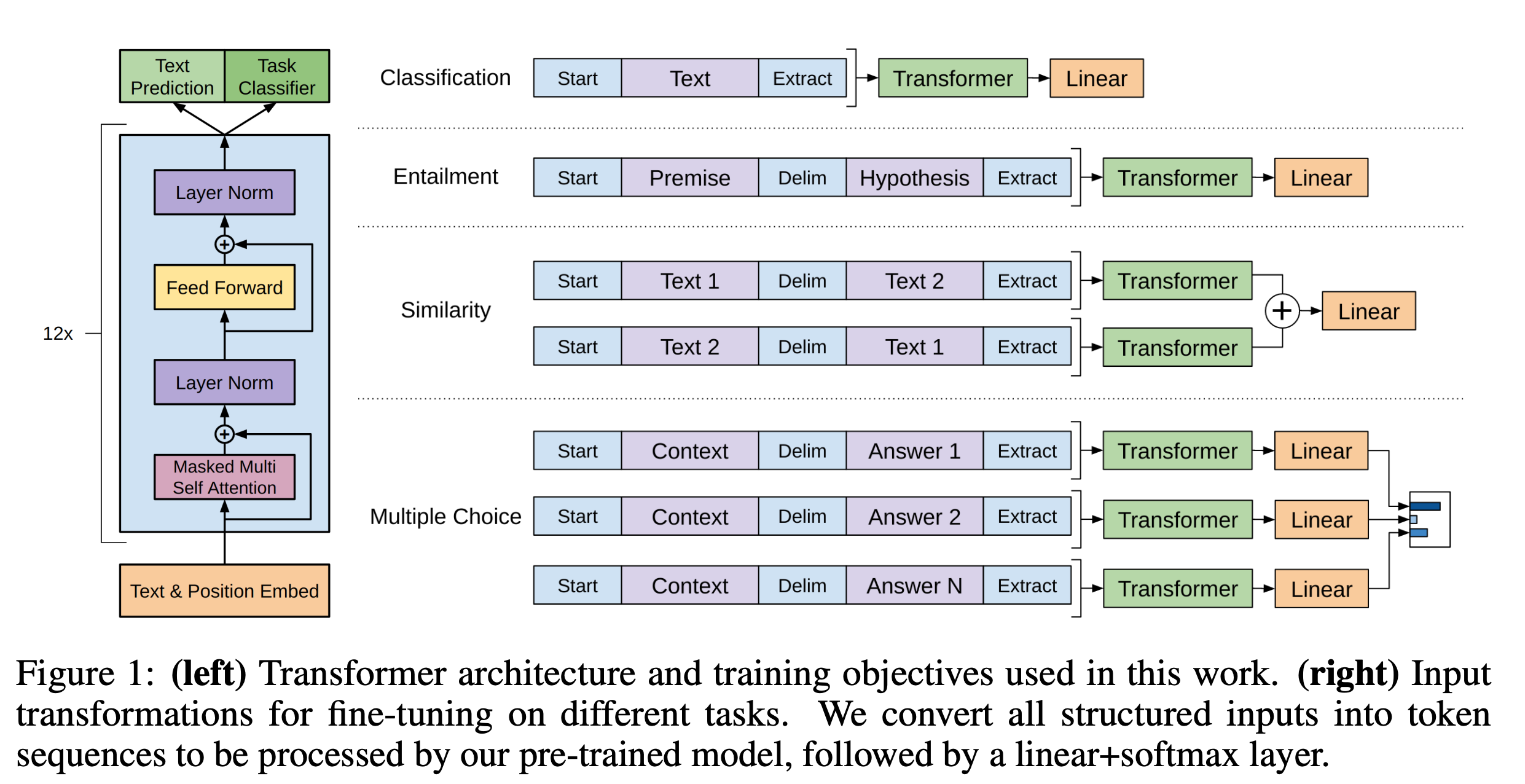
- 传统的语言模型:大量的标注数据进行监督学习;GPT:可以从大量未标注数据中学习语言知识和语言表示。
- GPT的学习模式为:大量无标注数据的Pretrain + 下游有标注数据的 Finetune。框架基本和BERT一致。
- 使用多层Transforme结构对大量训练语料做预训练,单向,给定当前位置之前部分的输入,预测当前位置的Token的输出,可参考类比n-gram。比如“我喜欢看书”,通过输入“我”来预测“喜”,通过输入“我喜”来预测“欢”,通过“我喜欢”来预测“看”,以此类推。(BERT是自编码式,如“我喜欢[MASK]书”,来预测“看”。
- finetune。增加linear层微调拟合
- 数据来源:Web,BookCorpus,Wiki等,“China is a country in Asia and has a population more than 1B ”
GPT-2
- GPT2延续了GPT的风格,训练数据更多,transformer层数更多,模型更大,但突出特点是没有Finetune,测试时无需标注数据,也不需要显示指定任务和模式,直接测试。
- 去掉了Finetune层,认为只要数据足够多足够大,模型可以自己学到测试的是什么任务,但任务测试中可能会有提示,如“文本+TL;DR:”(too long; didn’t read)
- GPT2表现并不如Finetune的模型,效果也没有BERT好。因此在很多实际应用上,还是会加Finetune层。
GPT-3
- 模型结构
- GPT3是一个 1750亿参数(aka.175B)的自回归语言模型,不使用Finetune.
- 模型基本和GPT2一致,参数更多,96层的Transformer层,模型参数达到了史无前例的1750亿,作为比较,Bert-base1.15亿,Bert-large参数3.4亿。并且使用了一共45TB的海量数据进行训练。
- 推断方式
- 在没有微调的情况下,使用Few/One/Zero-shot中测试其性能达到了很好的效果。
- zero-shot,即直接要求给答案;one-shot,给一个例子作为prompt,然后要答案;few-shot,给几个例子做prompt,然后要答案。
- 效果
- GPT3 可以生成人类评估者难以区分与人类撰写的文章的新闻文章样本。
- 比GPT和GPT2更擅长做生成任务,效果更好。
gpt3文章生成能力
GPT-3.5
[official doc] (https://openai.com/research/instruction-following)
- instructGPT是一种能很好的识别用户意图的语言模型,它比GPT3相比能获得更真实更健康的回复内容。
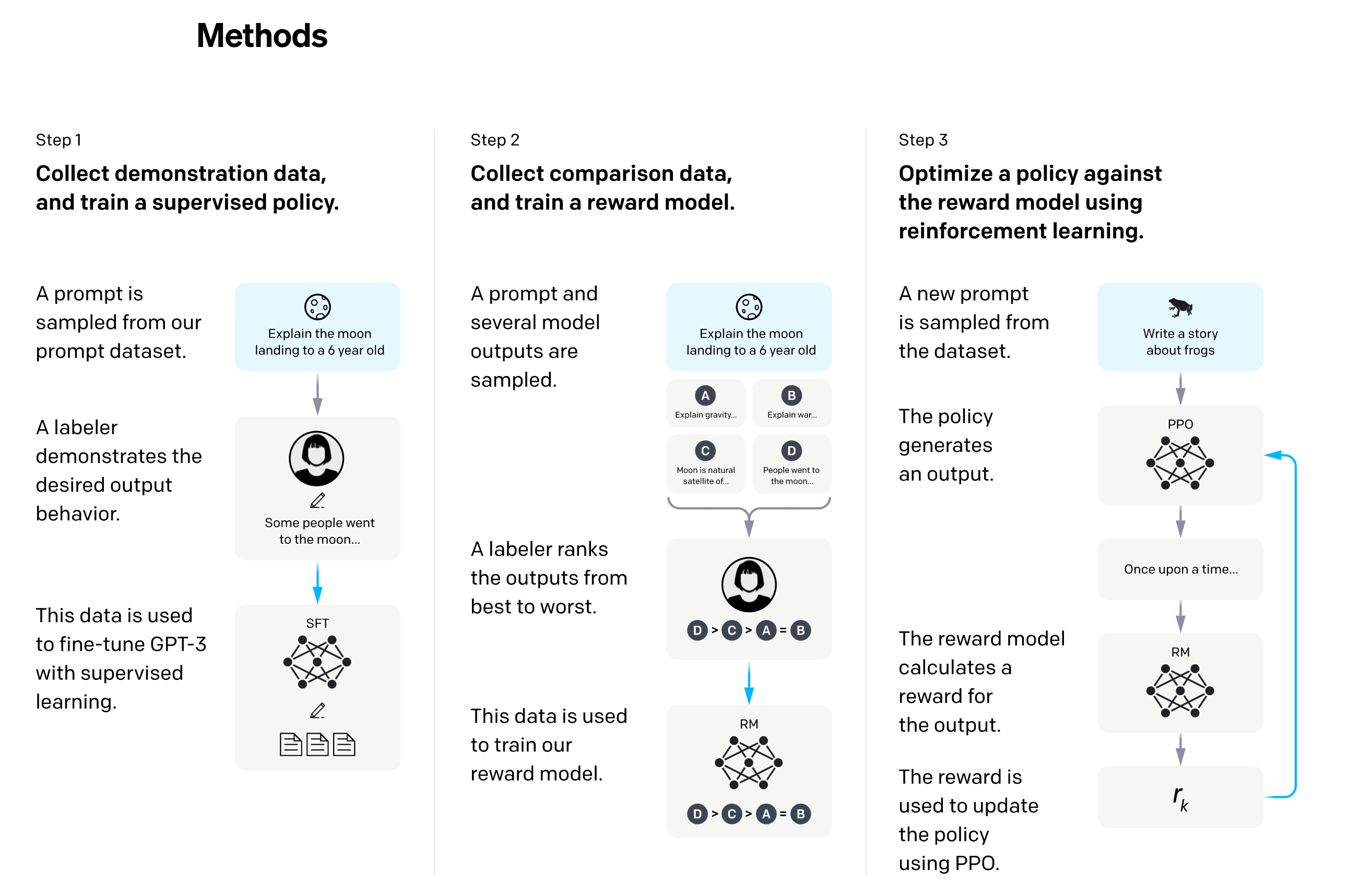
- 第一个步骤。GPT3.5 已经是比较强大的语言模型,可以给出较好的生成内容。但是在chat领域,不同的人给的问题或者指令千差万别,这时候GPT3.5其实还是比较难理解不同人的不同意图。所以为了让GPT3.5 更好的理解意图,第一阶段的监督训练是必不可少的。而且这一阶段是需要专业的标注人员参与。具体来讲,会从用户的提交的prompt(问题)中抽取一批数据,然后人工标注好<prompt, answer>,这批高质量的标注数据就可以用来对GPT3.5模型进行finetune。经过这一轮有监督的学习,针对先前对用户意图不太理解的内容,目前可以有一个较好的理解。所以此处可以看出,高质量的有监督训练数据是关键。
- 第二个步骤,主要任务是训练Reward Model(奖励模型)。通俗理解就是,我们用以下方法来训练模型,即符合我们意图的回答得到正向的奖励,否则不奖励或者被惩罚,通过这种机制,就可以迫使模型参数调整到一个尽可能输出符合用户意图的的答案的效果。
- 首先依然是抽取人工提交的prompt(指令或者问题),然后让步骤一训练好的模型来输出不同的答案(<prompt,answer1>,<prompt,answer2>….<prompt,answerK>),这时候这些输出答案通过人工按照一定的标准(比如相关性,流畅度,信息丰富性,安全性等等)来给这些答案进行排序(answer3 > answer1 > answer2 > …… > answerK);
- 以上就可以得到一系列的排序结果。那么就可以利用这些排序结果来训练奖励模型了。具体来讲,一种可能得方式是(也有可能通过ELO打分来实现https://www.biaodianfu.com/elo-glicko-trueskill.html)通过pair-wise learning to rank的机制来训练奖励模型。针对K个输出,我们通过两两组合输入到模型中,针对每一个输入都会给出一个奖励分。比如如果在排序中,answer3 排在answer1前面,那么pair-wise的loss函数就会迫使奖励模型对<prompt,answer3>比对<prompt,answer1>的打分更高。通过该步骤的训练,奖励模型就可以对哪些是高质量的回答,哪些是低质量的回答有了较好的理解和分值输出
- 第三个步骤的训练不再需要外部训练数据,而是采用强化学习来增自身模型的能力,采用的方法是这样的,首先步骤一中训练好的模型可以对不同的prompt输出不同的回答,步骤二训练好的奖励模型可以针对这些回答进行打分,那么这就可以形成一个回馈奖励机制,这个过程就是强化学习的过程。具体来讲,在这个步骤中,会使用不同于前面的步骤的prompt(为了增强泛化能力),然后使用步骤一训练好的模型来初始化PPO模型(https://openai.com/blog/openai-baselines-ppo/),通过该模型给出不同回答输出,该输出会经由奖励模型进行打分,打分之后的结果会返回到PPO模型进行有监督训练,从而再次给出不同的输出,再由奖励模型打分,再反馈到PPO模型进行有监督训练……如此训练往复几遍,模型的输出质量就会越来越高。(即用step1、step2的两个模型自我迭代)
GPT-4
多模态模型(输入图片+文本,输出文本),在很多专业&学术benchmark上展现出human-level的效果。
相关知识
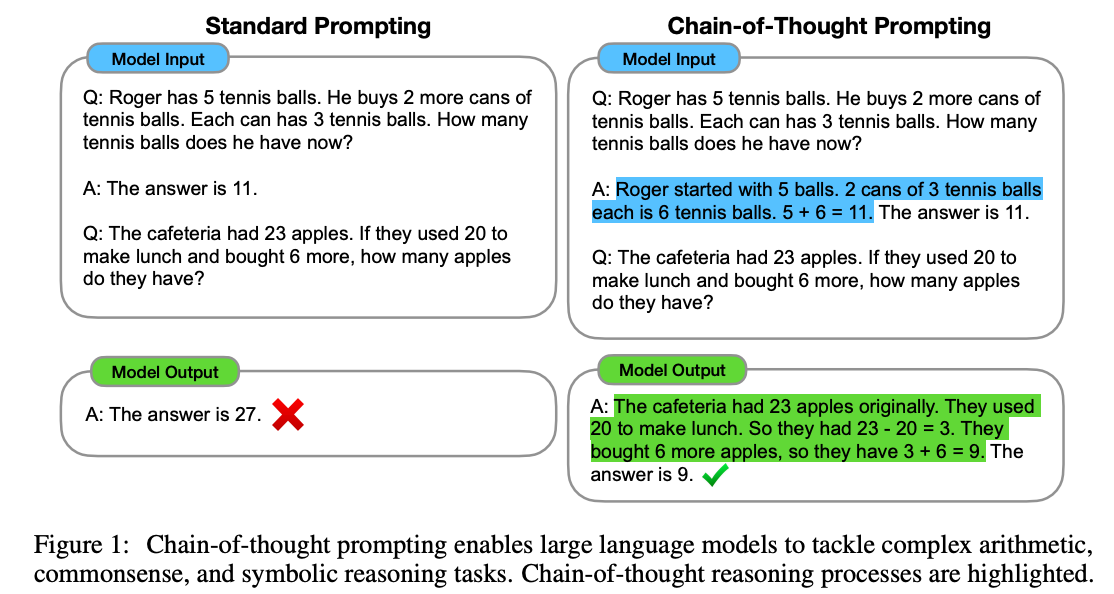
- chain of thought prompt
- PPO优化方法
- 在chatGPT的强化学习过程中,模型用到了PPO (Proximal Policy Optimization)优化方法,这是强化学习中常用的方法,也是目前OpenAI首选的强化学习优化方法。它能获得比当前SOTA方法相当甚至更好的性能表现,同时这种优化方法更加简单和容易调优。