From Wikipedia
- GeoHash是什么
Geohash is a public domain geocode system invented in 2008 by Gustavo Niemeyer which encodes a geographic location into a short string of letters and digits. Similar ideas were introduced by G.M. Morton in 1966.It is a hierarchical spatial data structure which subdivides space into buckets of grid shape, which is one of the many applications of what is known as a Z-order curve, and generally space-filling curves.
- GeoHash的特性
Geohashes offer properties like arbitrary precision and the possibility of gradually removing characters from the end of the code to reduce its size (and gradually lose precision). Geohashing guarantees that the longer a shared prefix between two geohashes is, the spatially closer they are together. The reverse of this is not guaranteed, as two points can be very close but have a short or no shared prefix.
- GeoHash的有趣历史
The core part of the Geohash algorithm and the first initiative to similar solution was documented in a report of G.M. Morton in 1966, “A Computer Oriented Geodetic Data Base and a New Technique in File Sequencing”. The Morton work was used for efficient implementations of Z-order curve, like in this modern (2014) Geohash-integer version (based on directly interleaving 64-bit integers), but his geocode proposal was not human-readable and was not popular. Apparently, in the late 2000s, G. Niemeyer still didn’t know about Morton’s work, and reinvented it, adding the use of base32 representation. In February 2008, together with the announcement of the system, he launched the website http://geohash.org, which allows users to convert geographic coordinates to short URLs which uniquely identify positions on the Earth, so that referencing them in emails, forums, and websites is more convenient. Many variations have been developed, including OpenStreetMap’s short link (using base64 instead of base32) in 2009, the 64-bit Geohash in 2014, the exotic Hilbert-Geohash[5] in 2016, and others.
1. GeoHash数学原理
GeoHash是一种编码方式,采用32进制。注意这里和经纬度还没有任何关系。

GeoHash本质上是空间索引的一种方式,其基本原理是将地球理解为一个二维平面,将平面递归分解成更小的子块,每个子块在一定经纬度范围内拥有相同的编码。以GeoHash方式建立空间索引,可以提高对空间poi数据进行经纬度检索的效率。
demo讲解
编码
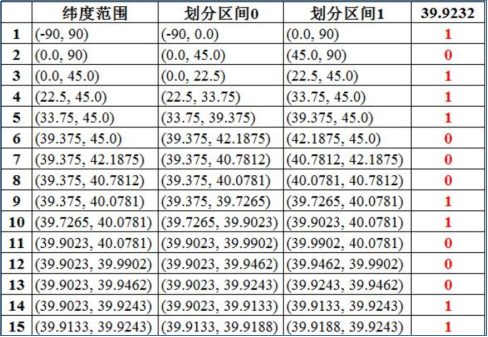
以经纬度值:(116.389550, 39.928167)进行算法说明。注意分割采用二分 对纬度39.928167进行逼近编码 (地球纬度区间是[-90,90])
-
如果给定的纬度x(39.928167)属于左区间,则记录0,如果属于右区间则记录1 区间[-90,90]进行二分为[-90,0),[0,90],称为左右区间,可以确定39.928167属于右区间[0,90],给标记为1
-
接着将区间[0,90]进行二分为 [0,45),[45,90],可以确定39.928167属于左区间 [0,45),给标记为0
-
递归上述过程16次,39.928167总是属于某个区间[a,b]。随着每次迭代区间[a,b]总在缩小,并越来越逼近39.928167
同理,地球经度区间是[-180,180],可以对经度116.389550进行编码。
通过上述计算, 纬度产生的编码为1 1 0 1 0 0 1 0 1 1 0 0 0 1 0,经度产生的编码为1 0 1 1 1 0 0 0 1 1 0 0 0 1 1
合并:偶数位放经度,奇数位放纬度,把2串编码组合生成新串如下图

将11100 11101 00100 01111 0000 01101转成十进制,5个一组,对应着28、29、4、15,0,13 十进制对应的base32编码就是wx4g0e。
解码
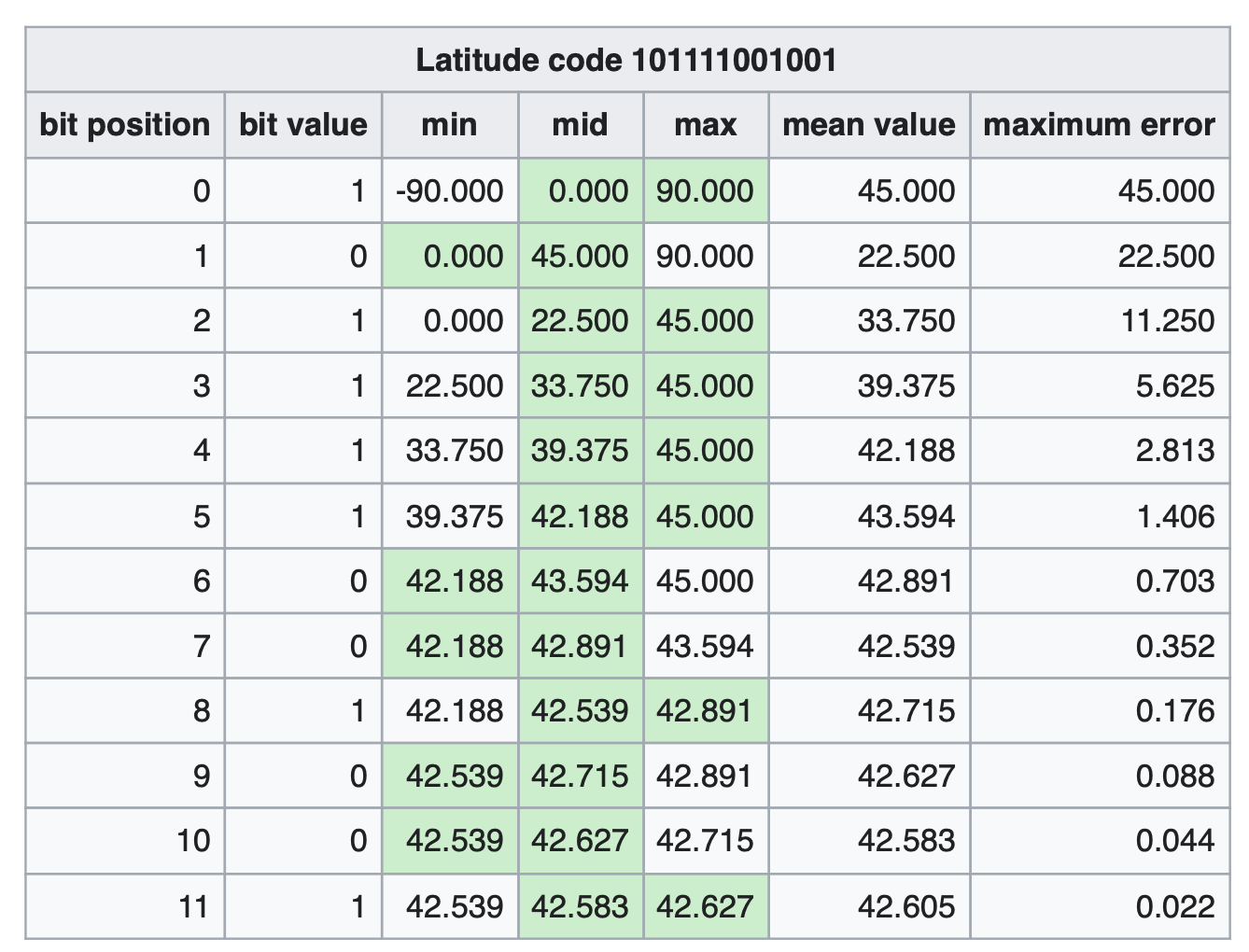
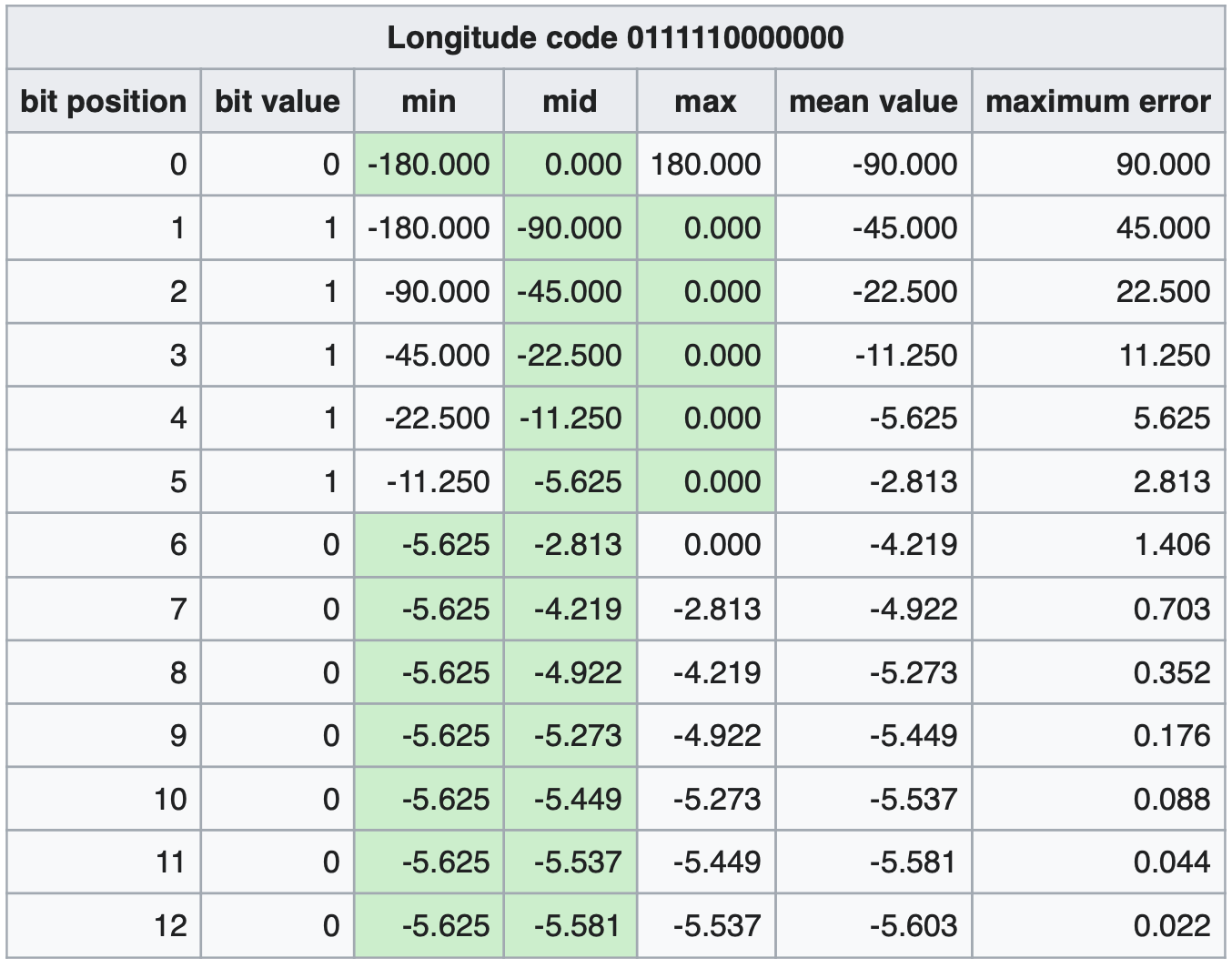
Geohash其实就是将整个地图或者某个分割所得的区域进行一次划分,由于采用的是base32编码方式,即Geohash中的每一个字母或者数字(如wx4g0e中的w)都是由5bits组成(2^5 = 32,base32),这5bits可以有32中不同的组合(0~31),这样我们可以将整个地图区域分为32个区域,通过00000 ~ 11111来标识这32个区域。第一次对地图划分后的情况如下图所示(每个区域中的编号对应于该区域所对应的编码)。
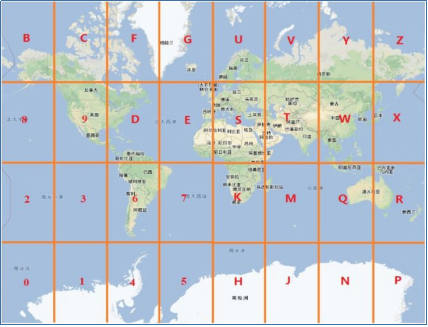
trick
Geohash的0、1串序列是经度0、1序列和纬度0、1序列中的数字交替进行排列的,偶数位对应的序列为经度序列,奇数位对应的序列为纬度序列,在进行第一次划分时,Geohash0、1序列中的前5个bits(11100),那么这5bits中有3bits是表示经度,2bits表示纬度,所以第一次划分时,是将经度划分成8个区段(2^3 = 8),将纬度划分为4个区段(2^2 = 4),这样就形成了32个区域。
同理,可以按照第一次划分所采用的方式对第一次划分所得的32个区域各自再次划分。
1位精度的geohash编码为例,如下图
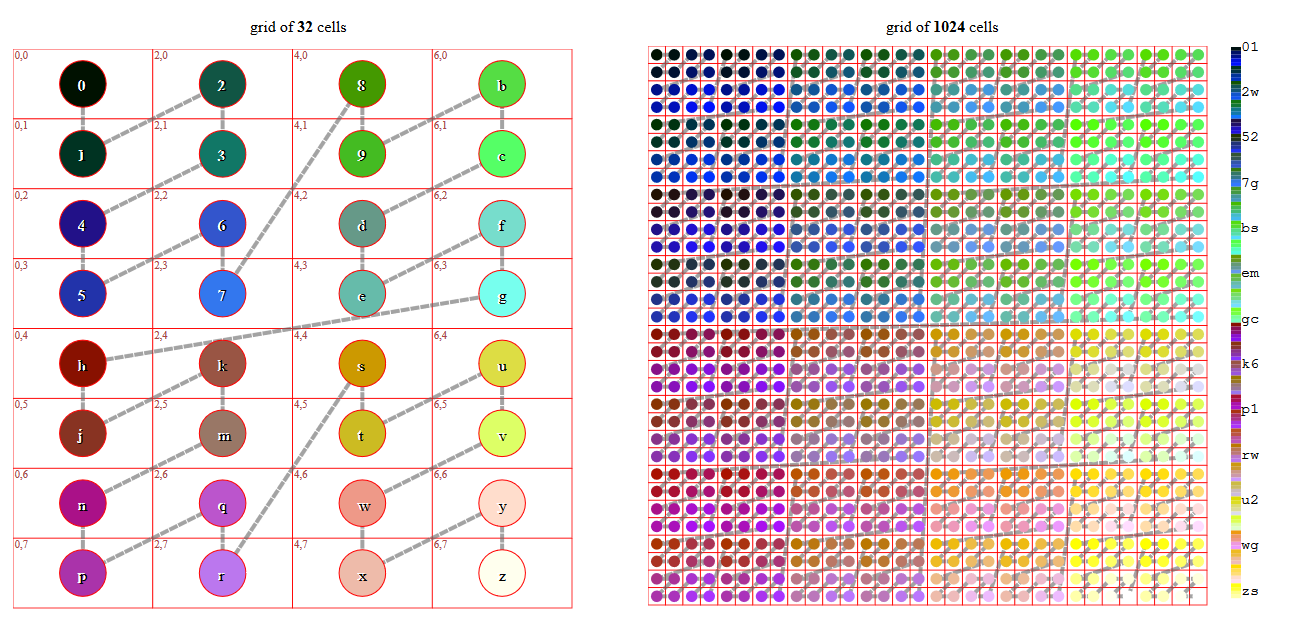
1
2
3
4
5
6
7
8
9
10
偶数位放经度,奇数位放纬度
编号->二进制->经度->纬度
0 -> 00000 -> 00 -> 000
1 -> 00001 -> 00 -> 001
2 -> 00010 -> 01 -> 000
3 -> 00011 -> 01 -> 001
4 -> 00100 -> 00 -> 010
5 -> 00101 -> 00 -> 011
(0,1,4,5)在一个经度,(2,3)在一个经度
(0,2), (1,3), (4), (5)各在一个纬度
2. 应用
思路
GeoHash将二维的经纬度转换成字符串,比如下图展示了北京9个区域的GeoHash字符串,分别是WX4ER, WX4G2, WX4G3等等,每一个字符串代表了某一矩形区域。也就是说,这个矩形区域内所有的点(经纬度坐标)都共享相同的GeoHash字符串,这样既可以保护隐私(只表示大概区域位置而不是具体的点),又比较容易做缓存。
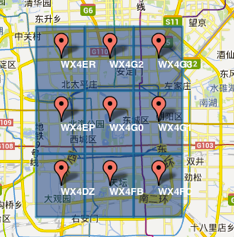
比如左上角这个区域内的用户不断发送位置信息请求餐馆数据,由于这些用户的GeoHash字符串都是WX4ER,所以可以把WX4ER当作key,把该区域的餐馆信息当作value来进行缓存,而如果不使用GeoHash的话,由于区域内的用户传来的经纬度是各不相同的,很难做缓存。这里的insight就是离散/分桶,通过这种方式将连续的经纬度分桶,从而容易缓存检索。
Geohash编码中,字符串相似的表示距离相近(特殊情况后文阐述),这样可以利用字符串的前缀匹配来查询附近的POI信息。如下两个图所示,一个在城区,一个在郊区,城区的GeoHash字符串之间比较相似,郊区的字符串之间也比较相似,而城区和郊区的GeoHash字符串相似程度要低些。此外,不同的编码长度,表示不同的范围区间,字符串越长,表示的范围越精确。
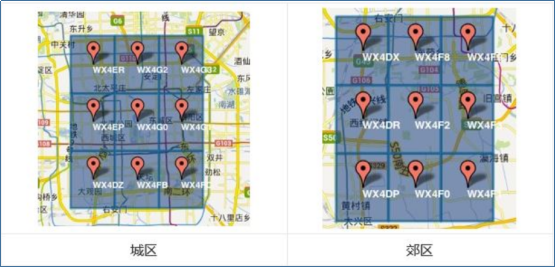
GeoHash天然把距离+方向都编码了
POI+GeoHash缺点
由于GeoHash是将区域划分为一个个规则矩形,并对每个矩形进行编码,这样在查询附近POI信息时会导致以下问题,比如红色的点是我们的位置,绿色的两个点分别是附近的两个餐馆,但是在查询的时候会发现距离较远餐馆的GeoHash编码与我们一样(因为在同一个GeoHash区域块上),而较近餐馆的GeoHash编码与我们不一致。这个问题往往产生在边界处。
解决的思路很简单,我们查询时,除了使用定位点的GeoHash编码进行匹配外,还使用周围8个区域的GeoHash编码,这样可以避免这个问题。
我们已经知道现有的GeoHash算法使用的是Peano空间填充曲线,这种曲线会产生突变,造成了编码虽然相似但距离可能相差很大的问题,因此在查询附近餐馆时候,首先筛选GeoHash编码相似的POI点(比如当前+周围8个),然后进行实际距离计算。
3. 填充曲线
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线,当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子快也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
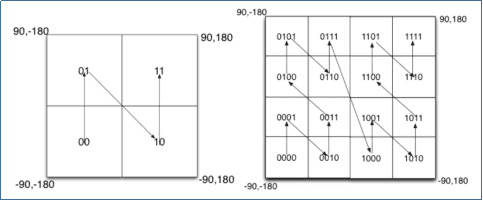
Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
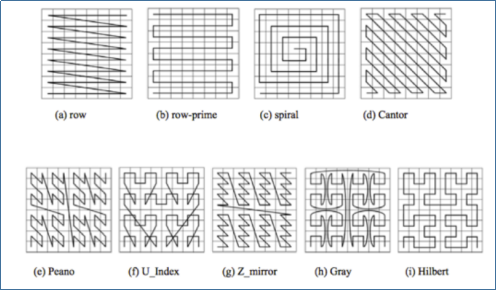
除Peano空间填充曲线外,还有很多空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。但是由于Peano曲线实现更加简单,在使用的时候配合一定的解决手段,可以很好的满足大部分需求
4. GeoHash作为特征的实践
Cell Size
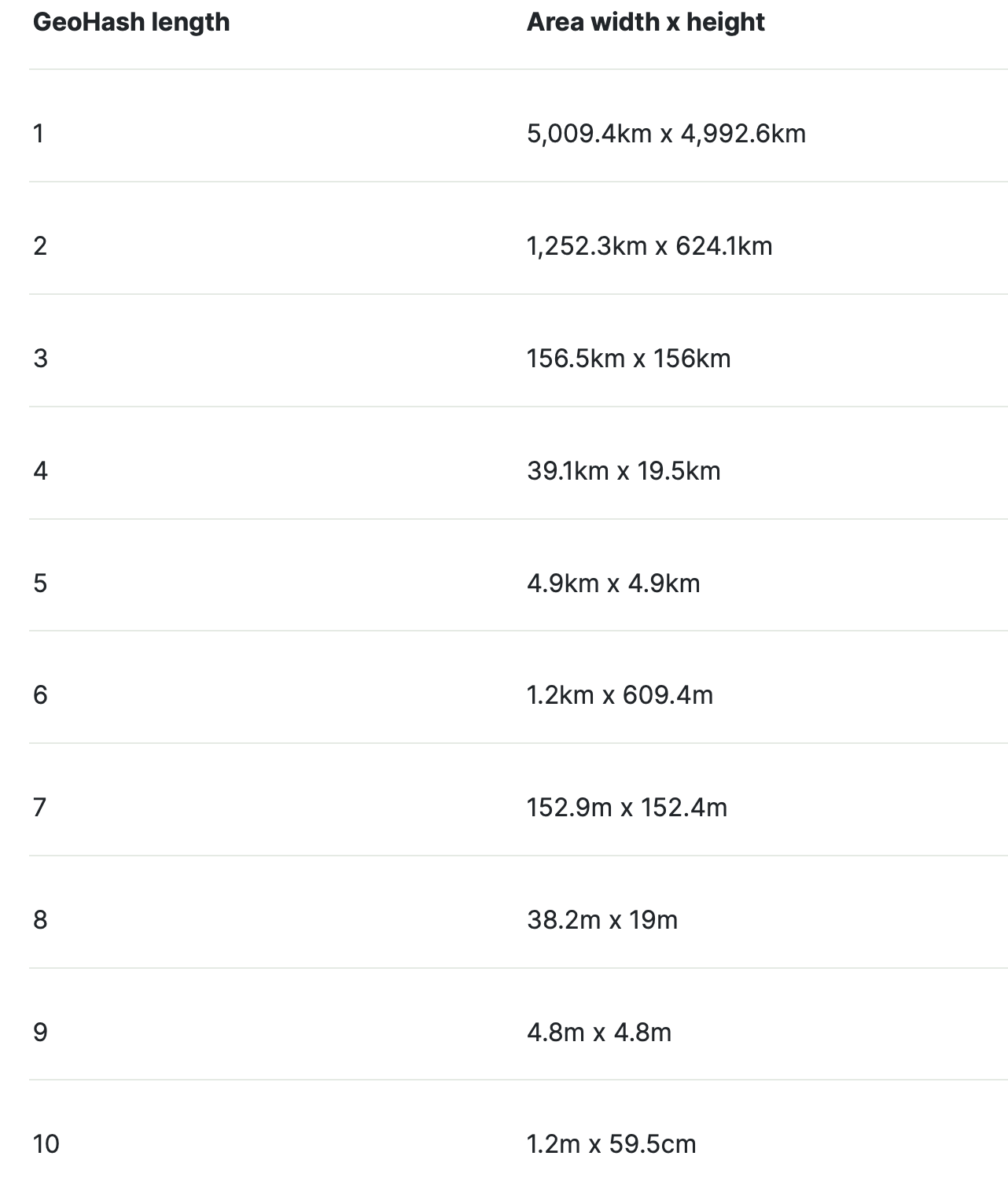 5位即
5位即5*5=25, 13个纬度,12个经度, 所以经纬度长宽不一样。
6位即 5*6=30, 15个纬度,15个经度,所以经纬度长宽一样。
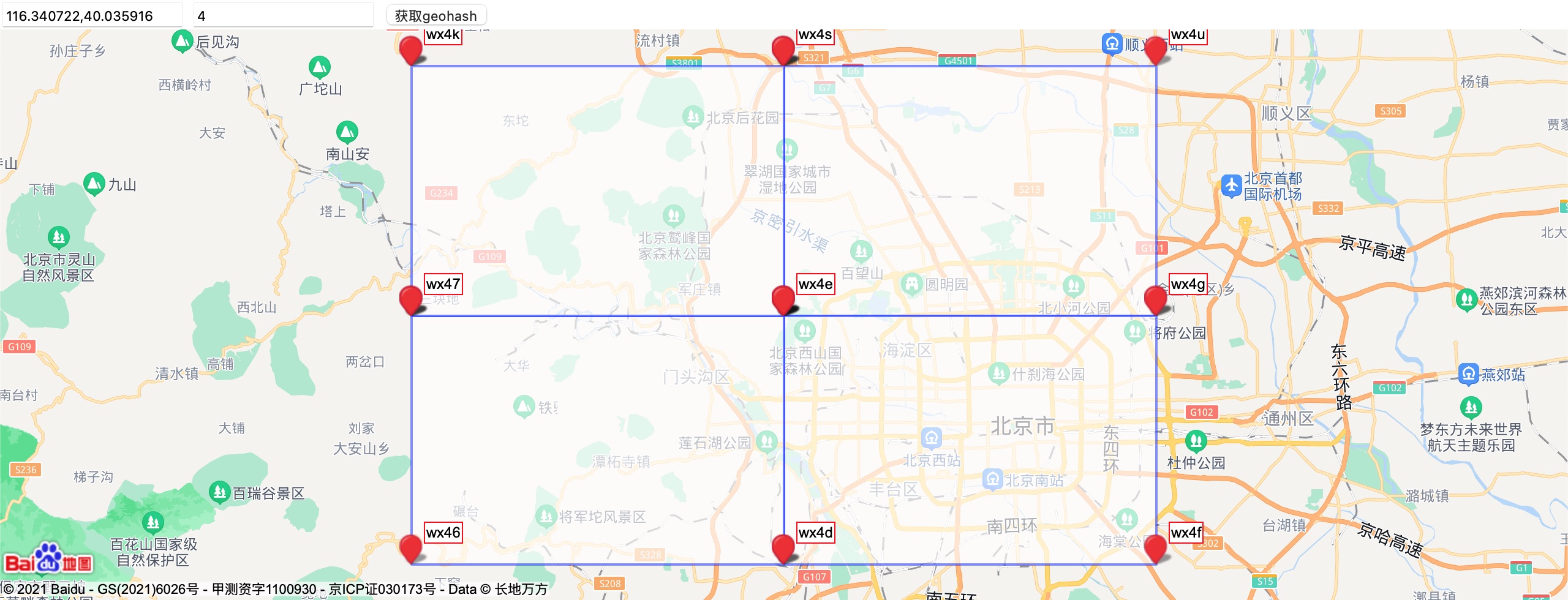
下面几个图实际感受geo4,geo5,geo6的空间尺度。
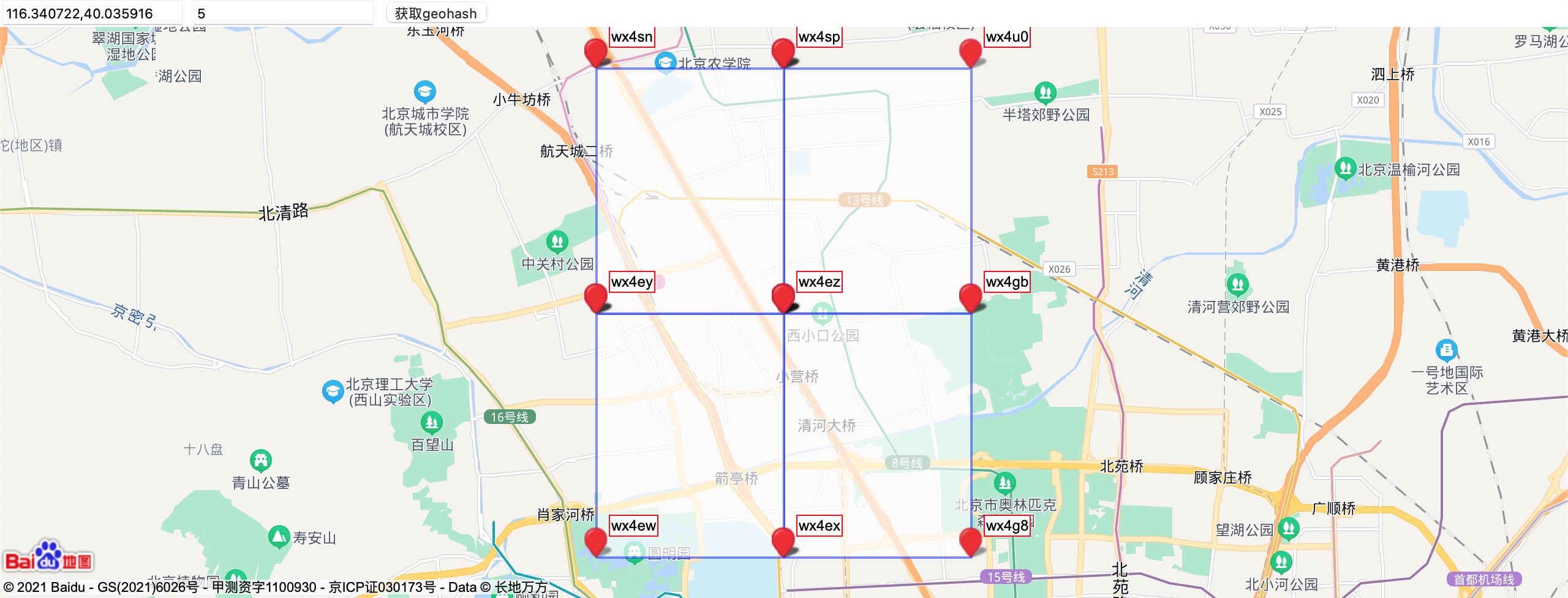
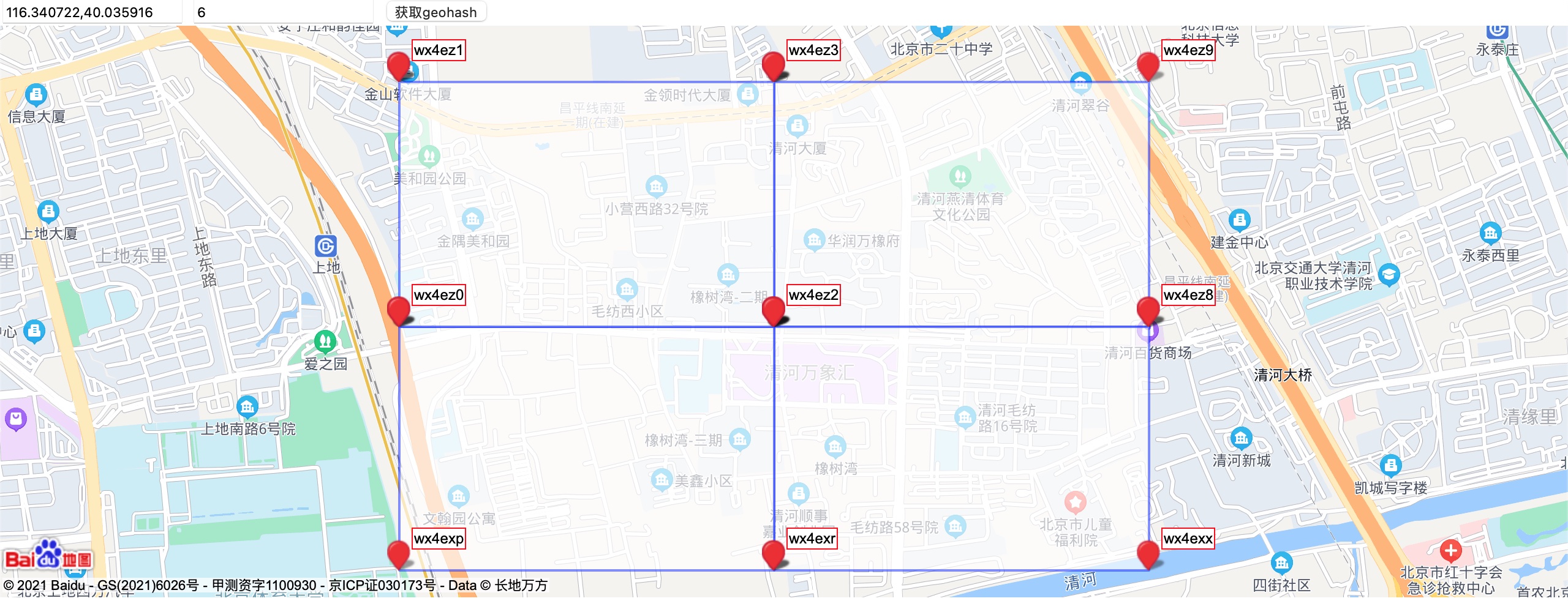
Hash Size
中国960万平方千米,计算不同的GeoHash位数会产生多少个cell,从而确定对应的Hash Size.
1
2
3
Geo4 = 960*10^4/39.1/19.5 = 1.25w
Geo5 = 960*10^4/4.9/4.9 = 40w
Geo6 = 960*10^4/1.2/0.6 = 13m